A new SIGMOD ’26 tutorial paper—“Data Agents: Levels, State of the Art, and Open Problems” puts a clear taxonomy on a problem most enterprises already feel: vendor messaging claims “agentic analytics,” but day-to-day delivery often looks like chat-with-your-warehouse.
Enterprise Data Agents Levels: Are You Stuck at Level 1 AI Analytics?
Better models don’t fix broken coordination across systems, tools, governance, and verification loops.
McKinsey reports 88% of organizations use AI in at least one business function, yet most are still early in scaling agentic systems.
Gartner forecasts up to 40% of enterprise apps will include task-specific AI agents by 2026 demand is accelerating fast.
So how do you tell whether you’re buying “agent washing” versus real autonomy?
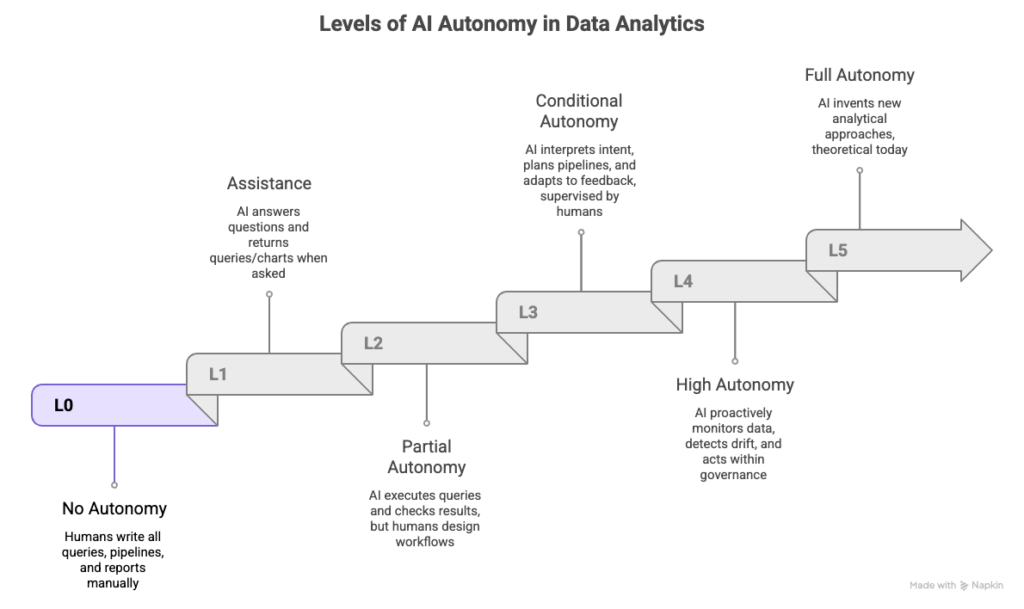
The L0–L5 Taxonomy: An Autonomy Reality Check
The SIGMOD ’26 “Data Agents” work adopts a six-level hierarchy L0 to L5, explicitly inspired by the SAE autonomy framing used in autonomous driving.
Use this as your litmus test: “Who owns the workflow human or agent?”
Level 0 (L0): No autonomy
Humans do everything manually: extract, join, validate, explain.
Level 1 (L1): Assistant / single-step help
The system answers questions, drafts SQL, suggests charts but doesn’t own the workflow end-to-end.
Level 2 (L2): Partial autonomy inside a human-designed pipeline
The agent can use tools and self-correct within boundaries but humans still architect and coordinate the overall plan.
Level 3 (L3): Workflow autonomy (the real inflection point)
You state the objective. The agent plans, executes, validates, and iterates across systems with minimal micromanagement.
Level 4 (L4): Proactive autonomy
Agents anticipate needs, monitor drift, trigger actions, and escalate exceptions.
Level 5 (L5): Full autonomy
A “fully autonomous data scientist” that can generate new analyses and artifacts with broad responsibility.
Remember this: the jump to L3 is not incremental. It requires planning + execution + validation loops, plus governance, safety, and observability built into the core not bolted on later.
What “Stuck at L1” Looks Like in the Real World
1) The fraud detection trap
A bank deploys “AI fraud analytics.” It queries transactions well. But fraud patterns require correlating customer profiles, device fingerprints, merchant risk, and watchlists across multiple systems.
If your tool can only answer from one silo at a time, your “agent” is L1 and the workflow is still effectively L0.
2) The supply chain blind spot
A manufacturer’s agent answers inventory questions. But when asked:
“What’s driving margin erosion across top SKUs, factoring supplier costs, logistics delays, and demand shifts?”
…it returns partial results from one system and leaves humans to stitch the rest.
That’s classic L1 behavior: question answering without orchestration.
Why the Industry Is Converging on Multi-Agent Orchestration
Enterprises are arriving at the same conclusion: complex work needs specialized agents coordinated by an orchestrator, not one monolithic “do everything” model.
- Anthropic reported that a lead-agent + sub-agent architecture outperformed a single-agent baseline by 90.2% on an internal research evaluation.
- AgenticData (research system) uses a multi-agent design (profiling, planning, manipulation, validation/memory) to improve accuracy and reduce iteration cycles; it reports outperforming baselines by ~15–25% on benchmarks and reducing iteration counts by 10–80%.
The common thread: coordination + verification beats raw model strength once tasks become multi-step and multi-system.
The Four Bottlenecks Blocking Your Path to L3
If you’ve tried to move beyond pilot deployments, you’ve likely hit these:
- Cascading errors
One wrong join → wrong aggregation → wrong insight. L1 systems often fail confidently. - The orchestration gap
Real enterprise questions span CRM, ERP, warehouse, logs, tickets, and operational databases. Coordination is the hard part. - Bolted-on governance
As autonomy rises, you need audit trails, policy enforcement, lineage, and approvals designed into the runtime. - Static assumptions in dynamic environments
Schemas drift. Definitions change. Data distribution shifts. Systems that can’t adapt degrade silently.
What L3 Architecture Actually Looks Like
If L1 is “answer questions,” L3 is “run workflows responsibly.”
That usually requires specialized agents coordinated through an orchestration layer (tooling integration, memory, planning, validation, governance).
A practical L3 pattern looks like:
- Planning Agent: convert intent → executable multi-system plan
- Optimization Agent: choose efficient execution path (cost/latency/scan control)
- Execution Agent: run operations with audit + rollback hooks
- Simulation & Validation Agent: test outputs before production, catch cascading errors
- Interpretation Agent: translate results into decisions with confidence + lineage
This mirrors what modern research systems emphasize: multi-agent planning plus validation loops and tool integration layers (often discussed alongside MCP-style tool servers).
Example: “Churn Analysis” as an L3 Workflow
User request: “Analyze churn risk for our SME segment.”
L3 execution flow:
- Planning: identify required sources (warehouse transactions, CRM support tickets, usage logs)
- Optimization: pick joins + sampling strategies to avoid petabyte scans
- Execution: run queries/APIs with traceable steps
- Validation: detect schema mismatches and rerun simulations before finalizing
- Interpretation: produce insight with lineage + confidence
Output example:
“Churn risk is up 5% in SMEs, correlated with a 40% spike in API latency from usage logs validated against support ticket escalation volume.”
That’s the qualitative shift: the agent owns the workflow; humans supervise and decide.
The Three-Tier Ecosystem Emerging Around Enterprise Agents
You can see the market forming into layers:
- Tier 1: Hyperscalers providing compute and model infrastructure
- Tier 2: Incumbents embedding agents inside their platforms (powerful in-walled-garden, weaker cross-stack)
- Tier 3: Agent-native builders designing orchestration-first architectures from day one
Gartner has also warned that a large share of agentic AI initiatives will be scrapped if costs, value, and governance don’t hold another reason L3 requires architecture, not just features.
Where Do You Go from Here?
1) Assess your level honestly
If your “agent” answers questions from a single system and needs humans to coordinate everything else, you’re likely L1.
2) Prioritize orchestration over demos
Evaluate tools on whether they can plan + execute + validate across your actual environment.
3) Build governance into the core
Audit logs, policy enforcement, approvals, lineage, rollback, and observability can’t be afterthoughts at L3.
About AVALOKA
AVALOKA is building the orchestration layer for enterprise data autonomy.
If your AI is still answering questions instead of running workflows with validation, governance, and cross-system execution it’s time to upgrade the architecture.
Schedule a demo: info@guruvaisciences.org