
Enterprise organizations invest substantial time in LLM vendor evaluation. They construct detailed comparison spreadsheets. They test benchmark performance across standardized datasets. They score vendors against requirement matrices spanning dozens of criteria. The vendor achieving the highest aggregate score wins the contract and moves to deployment.
Then operational reality arrives. The evaluation metrics that drove vendor selection prove disconnected from production deployment success. Integration takes three times longer than estimated. Costs exceed projections. Performance on actual business tasks underperforms benchmark results.
This pattern repeats with predictable consistency across enterprise LLM deployments.
We analyzed vendor selection processes across 34 enterprise LLM implementations in financial services and healthcare sectors over 18 months. The analysis included pre-selection evaluation criteria, vendor scoring methodologies, and post-deployment performance outcomes measured against stated business objectives.
The correlation between high evaluation scores and successful production deployment: 0.31.
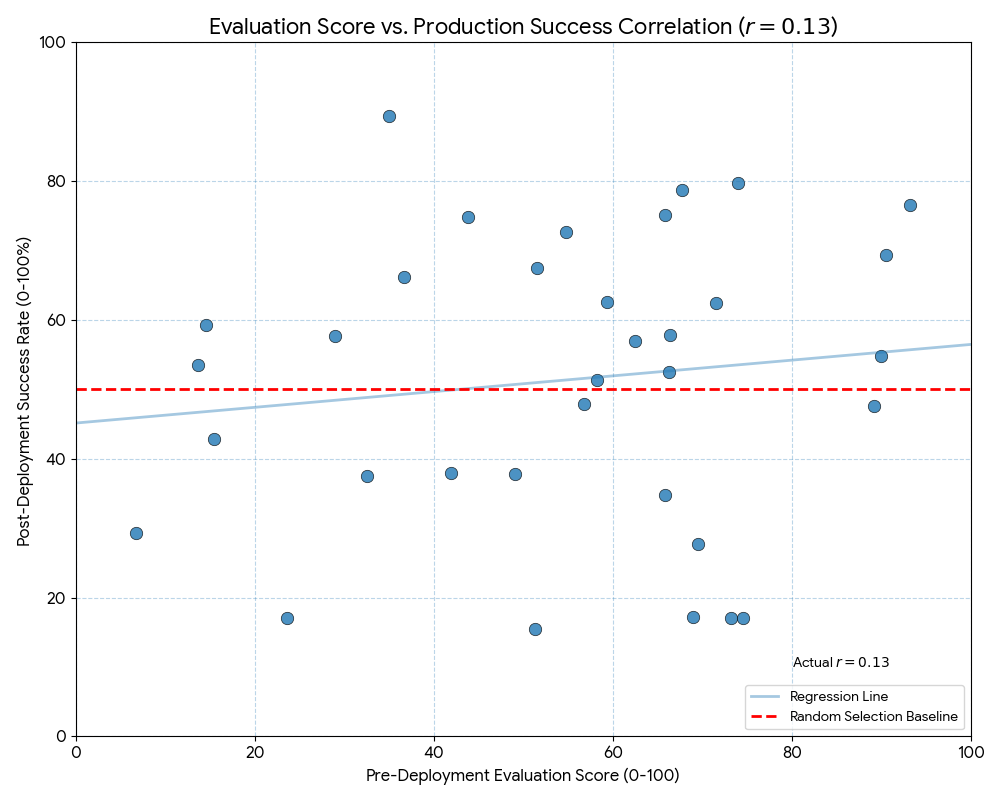
This figure indicates vendor evaluation frameworks commonly used in enterprise procurement barely predict operational success better than random selection. Organizations invest weeks or months in systematic vendor comparison only to achieve outcomes uncorrelated with their selection criteria.
The metrics that fail to predict success
Benchmark performance dominates most evaluation frameworks. Organizations test models against MMLU, HumanEval, or domain-specific standardized datasets. Vendors optimize specifically for these benchmarks. But benchmark performance often fails to translate to domain-specific task accuracy. A model scoring 85% on MMLU provides no useful prediction of its accuracy on loan underwriting decisions or medical record summarization—the actual business tasks organizations need to accomplish.
Feature checklists create similar problems. Vendors with longer feature lists score higher in evaluation matrices. But additional features create additional surface area for bugs and edge cases. Unused capabilities still consume maintenance resources and complicate system architecture. Feature quantity correlates weakly with production value delivery.
Demo performance in controlled vendor environments uses curated datasets and optimal configurations. Production deployment involves edge cases, malformed inputs, data quality issues, and integration complexity vendors cannot simulate in pre-sale demonstrations.
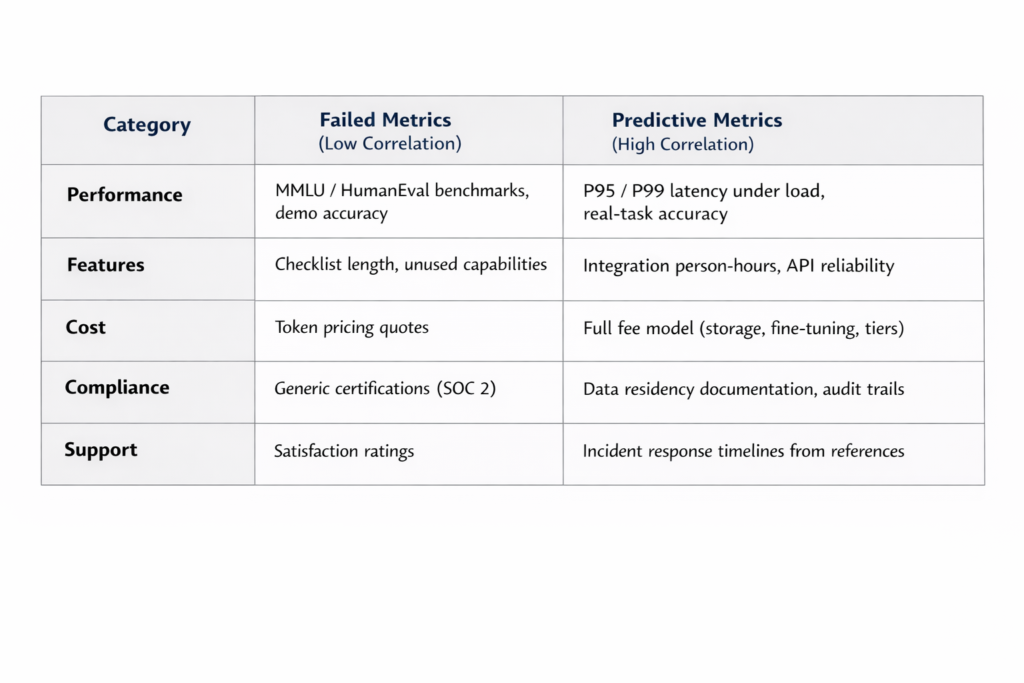
The metrics that actually predict success
Integration friction represents the person-hours required to connect vendor APIs to existing systems, configure data pipelines, implement security controls, and achieve production-ready deployment. Vendor estimates for integration timelines consistently underestimate actual requirements by 3-5x. Organizations should request integration hour data from reference customers rather than relying on vendor projections.
API reliability and rate limits determine production system behavior under realistic load conditions. Uptime SLAs sound impressive until undocumented rate limits throttle requests during peak usage. Production systems require consistent, predictable API behavior. Organizations should request P95 and P99 latency metrics under load conditions, not just average response times or theoretical maximum throughput.
Data residency and compliance controls determine where data actually processes, who maintains access, and how organizations audit model inputs and outputs. Generic compliance certifications (SOC 2, ISO 27001) don’t answer these questions with deployment-specific detail. Organizations need explicit documentation of data flow, processing locations, access controls, and audit capabilities.
Cost predictability at scale extends beyond token pricing to include minimum monthly commitments, volume tier breakpoints, charges for fine-tuning, storage costs, and custom deployment configurations. The invoice six months into production deployment rarely matches initial vendor quotes. Organizations should model total cost across realistic usage volumes including all fee components.
Incident response quality determines vendor behavior when model performance degrades, security incidents occur, or API outages impact production systems. Reference calls should focus specifically on problem scenarios rather than success stories. Questions should address incident response timelines, communication quality, and technical support effectiveness during actual production issues.
The evaluation framework structure
Effective vendor evaluation divides criteria into two distinct categories: threshold requirements and differential factors.
Threshold requirements represent pass/fail criteria. Security certifications, compliance capabilities, integration protocol support, API availability commitments. If vendors don’t meet threshold requirements, they’re eliminated from consideration. Don’t score threshold criteria on scales; they’re binary.
Differential factors require testing with organization-specific data and use cases. Not synthetic benchmarks or vendor-supplied datasets. Actual queries the production system will handle. Measure accuracy, latency, cost, and integration complexity using real requirements rather than theoretical scenarios.
The reference call methodology
Most organizations ask reference customers “are you happy with this vendor?” The response is predictably positive,nobody admits a poor vendor selection decision during reference calls arranged by that vendor.
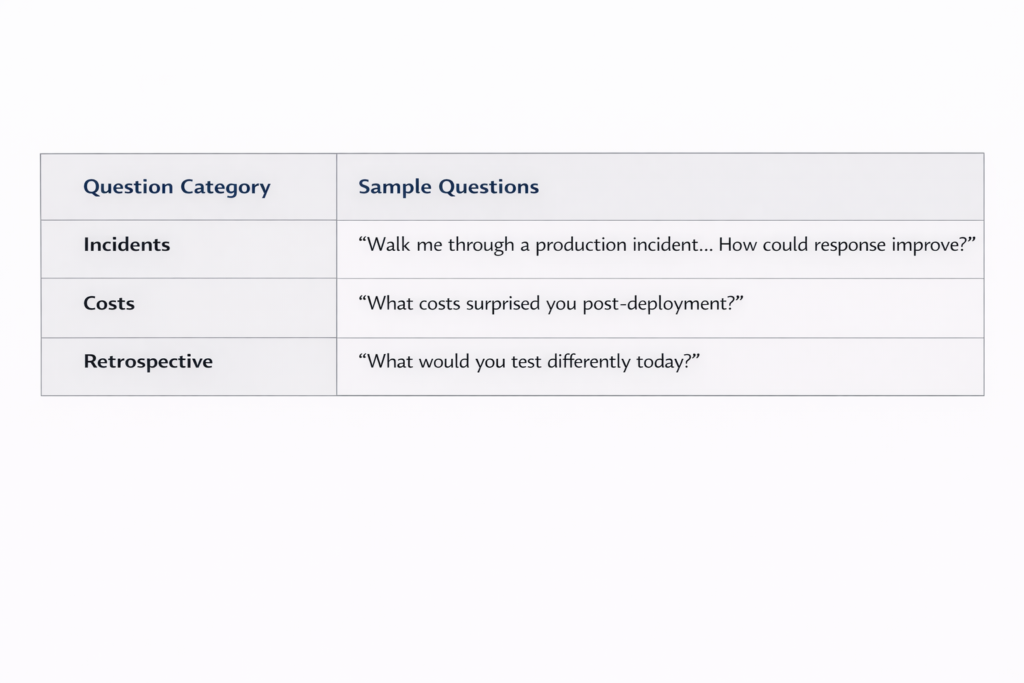
Useful reference calls ask operational specifics:
“Walk me through a production incident you experienced with this vendor. How did they respond? What aspects of their response could have improved?”
“What costs surprised you after deployment that weren’t clear in initial contracts?”
“If you were evaluating this vendor again today with current knowledge, what would you test differently during the evaluation phase?”
These questions extract operational detail rather than satisfaction ratings.
Vendor responses that signal risk
Certain vendor statements during evaluation conversations indicate higher implementation risk:
“We can customize that for your specific needs” translates to “this capability doesn’t exist yet,you’re funding its development through your contract.”
“Our product roadmap includes…” translates to “not available currently,your timeline depends on our engineering priorities.”
“We’re working with several Fortune 500 companies on similar deployments” translates to “nobody has completed this successfully yet, you’re the beta tester.”
Vendors describing current capabilities use present tense and offer reference to customers demonstrating those capabilities in production. Vendors describing future capabilities use conditional language and lack production references.
The systematic evaluation illusion
Detailed vendor comparison spreadsheets create the impression of systematic, data-driven decision-making. But operational success depends on testing what actually matters: integration friction measured in actual person-hours, cost predictability across complete fee structures, and API reliability under realistic production conditions.
Benchmark scores and feature comparison matrices matter substantially less than vendors want organizations to believe. The evaluation framework should optimize for operational reality, not theoretical capability demonstrations.
Organizations achieving successful LLM deployment outcomes consistently prioritize integration testing with real data, detailed cost modeling including all fee components, and reference calls focused on operational problems rather than vendor-curated success narratives. The spreadsheet scores become secondary to operational validation.
#LLMEvaluation #Agentic AI #AIBenchmarks #OperationalReality #IntegrationFriction #AICostPredictability #EnterpriseAI #GenAIDeployment #BeyondThePilot #TechProcurement